Migrations
ElectricSQL is designed to work with and on top of a Postgres data model. Once you have a data model, you use DDLX statements to expose parts of it, opting tables in to the Electric sync machinery and defining rules that control data access.
Electric does not impose a specific migrations system on you. Instead, you can use whichever migrations tooling you prefer to define your schema and apply DDLX statements. However, you must configure your migrations tooling to connect via the Migrations proxy.
Any migrations or DDL statements that alter electrified tables or use DDLX syntax must be applied via the Migrations proxy.
Your data model
Electric works with an existing Postgres data model, aka DDL schema. The workflow is to:
- opt tables into the Electric sync machinery by "electrifying" them
- grant and assign permissions to authorise data access using DDLX statements
You can then sync data to your local app using Shapes.
For example, assuming you have an existing table called projects, you can electrify it, grant read access to the public and write access to the project owner using e.g.:
ALTER TABLE projects
ENABLE ELECTRIC;
ELECTRIC ASSIGN 'projects:owner'
TO projects.owner_id;
ELECTRIC GRANT ALL
ON projects
TO 'projects:owner';
ELECTRIC GRANT SELECT
ON projects
TO ANYONE;
The ELECTRIC ASSIGN and ELECTRIC GRANT DDLX statements are work in progress.
See the Limitations section below and the Roadmap page for more context.
Creating a data model
If you need to create a data model, you can do so using SQL statements like CREATE TABLE, or a migrations tool like Prisma or Ecto.
Expand the box below for sample code:
Copy code to create data model
- SQL
- Prisma
CREATE TABLE users (
username text NOT NULL PRIMARY KEY,
inserted_at timestamptz NOT NULL,
updated_at timestamptz NOT NULL
);
CREATE TABLE projects (
id uuid NOT NULL PRIMARY KEY,
name text NOT NULL,
owner_id text NOT NULL REFERENCES users(username) ON DELETE CASCADE ON UPDATE CASCADE,
inserted_at timestamptz NOT NULL,
updated_at timestamptz NOT NULL
);
CREATE TABLE memberships (
project_id uuid NOT NULL REFERENCES projects(id) ON DELETE CASCADE ON UPDATE CASCADE,
user_id text NOT NULL REFERENCES users(username) ON DELETE CASCADE ON UPDATE CASCADE,
inserted_at timestamptz NOT NULL
);
CREATE TABLE issues (
id uuid NOT NULL PRIMARY KEY,
title text NOT NULL,
description text,
project_id uuid NOT NULL REFERENCES projects(id) ON DELETE CASCADE ON UPDATE CASCADE,
inserted_at timestamptz NOT NULL,
updated_at timestamptz NOT NULL
);
CREATE TABLE comments (
id uuid NOT NULL PRIMARY KEY,
content text NOT NULL,
author_id text NOT NULL REFERENCES users(username) ON DELETE CASCADE ON UPDATE CASCADE,
issue_id uuid NOT NULL REFERENCES issues(id) ON DELETE CASCADE ON UPDATE CASCADE,
inserted_at timestamptz NOT NULL,
updated_at timestamptz NOT NULL
);
datasource db {
provider = "postgresql"
url = env("PRISMA_DB_URL")
}
model User {
@@map("users")
username String @id
comments Comment[]
memberships Membership[]
projects Project[]
inserted_at DateTime @default(now())
updated_at DateTime @updatedAt
}
model Project {
@@map("projects")
id String @id @default(uuid())
name String
owner User @relation(fields: [owner_id], references: [username], onDelete: Cascade)
owner_id String
issues Issue[]
memberships Membership[]
inserted_at DateTime @default(now())
updated_at DateTime @updatedAt
}
model Membership {
@@map("memberships")
project Project @relation(fields: [project_id], references: [id], onDelete: Cascade)
project_id String
user User @relation(fields: [user_id], references: [username], onDelete: Cascade)
user_id String
inserted_at DateTime @default(now())
@@id([project_id, user_id])
}
model Issue {
@@map("issues")
id String @id @default(uuid())
title String
description String?
project Project @relation(fields: [project_id], references: [id], onDelete: Cascade)
project_id String
comments Comment[]
inserted_at DateTime @default(now())
updated_at DateTime @updatedAt
}
model Comment {
@@map("comments")
id String @id @default(uuid())
text String
author User @relation(fields: [author_id], references: [username], onDelete: Cascade)
author_id String
issue Issue @relation(fields: [issue_id], references: [id], onDelete: Cascade)
issue_id String
inserted_at DateTime @default(now())
updated_at DateTime @updatedAt
}
Using your migrations framework
You can use your prefered migrations tooling, often built into your backend framework if you have one, to both define your DDL schema and to apply DDLX statements. For example:
- Ecto
- Laravel
- Prisma
- Rails
- SQLAlchemy
With Phoenix/Ecto you can use the execute/1 function.
First, create a migration:
mix ecto.gen.migration electrify_items
Then e.g.:
defmodule MyApp.Repo.Migrations.ElectrifyItems do
use Ecto.Migration
def change do
execute "ALTER TABLE items ENABLE ELECTRIC"
end
end
With Laravel you can use the statement method on the DB facade.
First, create a migration:
php artisan make:migration electrify_items
Then use DB::statement in the up function:
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Support\Facades\DB;
return new class extends Migration {
public function up(): void {
DB::statement("ALTER TABLE items ENABLE ELECTRIC");
}
};
With Prisma you customize a migration to include an unsupported feature.
First, use the --create-only flag to generate a new migration without applying it:
npx prisma migrate dev --create-only
Open the generated migration.sql file and add the electrify call:
ALTER TABLE items ENABLE ELECTRIC;
Apply the migration:
npx prisma migrate dev
With Rails you can execute SQL in the change method of your migration class.
First, create a migration:
rails generate migration ElectrifyItems
Then e.g.:
class ElectrifyItems < ActiveRecord::Migration[7.0]
def change
execute "ALTER TABLE items ENABLE ELECTRIC"
end
end
With SQLAlchemy/Alembic you can use the Operations.execute method.
First, create a migration:
alembic revision -m "electrify items"
Then execute the SQL in the upgrade function:
# ... docstring and revision identifiers ...
from alembic import op
import sqlalchemy as sa
def upgrade():
op.execute('ALTER TABLE items ENABLE ELECTRIC')
See Integrations -> Backend and API -> DDLX for more information.
Migrations proxy
Schema migrations to electrified tables must be applied to Postgres via a proxy server integrated into the Electric application. This proxy server:
- enables DDLX syntax
- ensures consistent propagation of schema changes to client applications
- validates electrified tables to ensure they are supported by Electric
- supports type-safe Client generation using the CLI
generatecommand
DDL migrations not applied via the proxy are not captured by Electric. This is fine if they do not use DDLX syntax or do not affect the electrified part of your schema (it's also fine if they affect tables that are electrified later on).
However, if they do use DDLX syntax or do affect the electrified part of your schema, then they must be applied via the proxy. If not, they will be rejected and an error will be raised.
You do not need to route all your database access through the Migrations proxy. It is just intended to be used for DDL migrations, not for all your database writes and queries.
Normal DML access to your Postgres does not need to be routed via the Migrations proxy. If your app has a backend, it should connect and interact with your database directly and Electric will happily pick up on the changes.
You can either route all DDL access to your Postgres via the Migrations proxy, or just the subset of DDL that impacts Electrified tables and/or uses DDLX statements. Trying to change an electrified table or use a DDLX statement without going through the proxy will raise an error.
Configuring and connecting to the migrations proxy
The Electric sync service connects to a Postgres database at DATABASE_URL and, by default, exposes the migrations proxy as a TCP service on PG_PROXY_PORT, secured by PG_PROXY_PASSWORD. Instead of connecting your migrations tooling (or any interactive session applying migrations) to Postgres directly, connect to the Electric sync service instead.
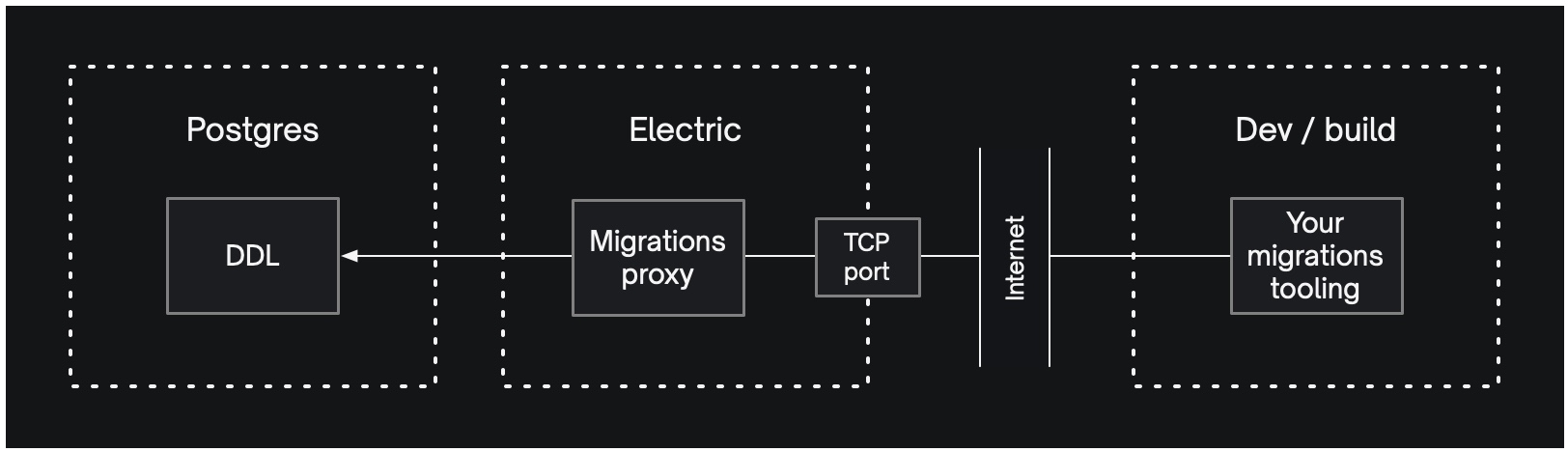
The migrations proxy intercepts your migrations, validates and transforms them and proxies them on to the Postgres at DATABASE_URL. Since the proxy speaks fluent Postgres, you can connect to it via any Postgres-compatible tool, e.g. psql -U postgres -p 65432 electric:
$ PGPASSWORD=${PG_PROXY_PASSWORD} psql -U postgres -p ${PG_PROXY_PORT} electric
electric=# CREATE TABLE public.items (id text, value text);
CREATE TABLE
-- since we're connecting via the proxy, the DDLX syntax will work
electric=# ALTER TABLE public.items ENABLE ELECTRIC;
ELECTRIC ENABLE
-- this alter table statement affects the newly electrified items table
-- and so will be captured and streamed to any connected clients
electric=# ALTER TABLE public.items ADD COLUMN amount integer;
ALTER TABLE
See API -> Sync service for more information about configuring the sync service and Deployment -> Concepts for a description of the different connection options.
Framework integration
Your framework of choice will need to be configured in order to pass migrations (and only migrations) through the proxy rather than directly to the underlying Postgres database.
This typically involves using a different database connection string for migrations, often by running your migrations command with a different DATABASE_URL that connects to the migrations proxy. However, as each framework has different requirements, we provide framework-specific example code for this in Integrations -> Backend.
If your framework of choice hasn't been documented yet, please feel free to raise a feature request or to let us know on Discord. We'll be happy to help you get up and running and ideally to work together to update the documentation.
Using the proxy tunnel
In some cases you may not be able to connect to the migrations proxy directly. For example, if your firewall or hosting provider don't support TCP access to the sync service on PG_PROXY_PORT. In these cases, you can use the Proxy tunnel to connect to the proxy using a TCP-over-HTTP tunnel.
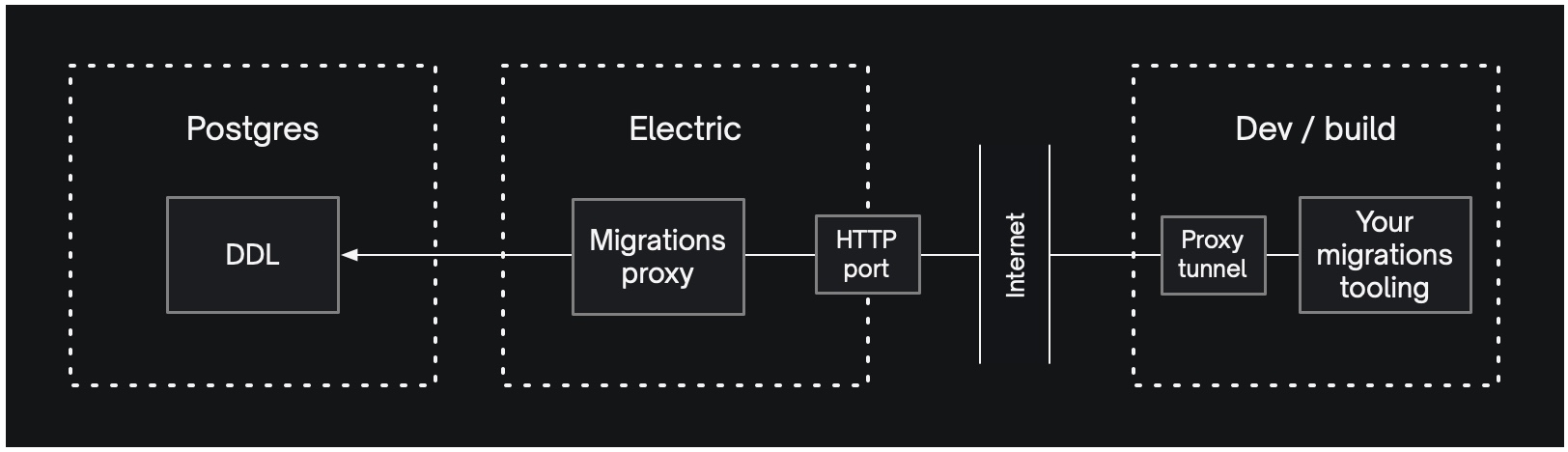
See API -> CLI & Generator and Deployment -> Concepts for more information about using the proxy tunnel and API -> Sync service on configuring the sync service to support it.
Limitations
There are currently a number of limitations on the data models and migrations that ElectricSQL supports.
Default schema
Only tables in the default schema named public can be electrified at the moment. We are working on lifting this restriction.
Table names
The client generator sanitises table names (because of an issue in an external library) removing any prefix that is not a letter and treating the first letter as case insensitive. As an example, electrifying the tables _myTable, 123myTable, myTable, and MyTable will all clash on table name, causing a generator error.
Forward migrations
We only currently support forward migrations. Rollbacks must be implemented as forward migrations.
Additive migrations
We only currently support additive migrations. This means you can't remove or restrict a field. Instead, you need to create new fields and tables (that are pre-constrained on creation) and switch / mirror data to them.
In practice this means that we only support this subset of DDL actions:
CREATE TABLEand its associatedALTER TABLE <table name> ENABLE ELECTRICcallALTER TABLE <electrified table> ADD COLUMNCREATE INDEX ON <electrified table>,DROP INDEX. Indexes can be created and dropped because they don't affect the data within the electrified tables.
No default values for columns
Currently it's not possible to electrify tables that have columns with DEFAULT clauses. This has to do with the fact that those clauses may include Postgres expressions that are difficult or impossible to translate into an SQLite-compatible one.
We will lift this limitation at some point, e.g. by discarding DEFAULT clauses in the SQLite schema or by supporting a limited set of default expressions.
Data types and constraints
See the pages on Types and Constraints.